bmp格式图片文件由4部分组成:文件头(BitmapFileHeader),信息头(BitmapInfoHeader),颜色表(RGBQuad),像素矩阵(RGB)[即数据区]。
文件头(BitmapFileHeader)
typedef struct _BITMAPFILEHEADER
{
BYTE2 bfType; //类型标识0x4d42
BYTE4 bfSize; //文件大小(字节)
BYTE2 bfReserved1; //保留1(0)
BYTE2 bfReserved2; //保留2(0)
BYTE4 bfOffBits; //数据区偏移(字节)
} BitmapFileHeader;信息头(BitmapInfoHeader)
typedef struct _BITMAPINFOHEADER{
BYTE4 biSize; //本结构的大小,根据不同的操作系统而不同,在Windows中,此字段的值总为0x28字节=40字节
BYTE4 biWidth; //图片宽度(px)
BYTE4 biHeight; //图片高度(px)
BYTE2 biPlanes; //目标设备的级别(1)
BYTE2 biBitCount; //每个像素所需的位数,必须是1(双色),4(16色),8(256色)或24(真彩色)之一
BYTE4 biCompression; //是否压缩(0不压缩)
BYTE4 biSizeImage; //图像数据区大小
BYTE4 biXPelsPerMeter; //水平分辨率,像素每米
BYTE4 biYPelsPerMeter; //垂直分辨率,像素每米
BYTE4 biClrUsed; //BMP图像使用的颜色,0表示使用全部颜色,对于256色位图来说,此值为0x100=256
BYTE4 biClrImportant; //重要的颜色数,此值为0时所有颜色都重要,对于使用调色板的BMP图像来说,
//当显卡不能够显示所有颜色时,此值将辅助驱动程序显示颜色
} BitmapInfoHeader;颜色表(RGBQuad)
typedef struct _RGBQUAD {
BYTE1 rgbBlue; //蓝色分量
BYTE1 rgbGreen; //绿色分量
BYTE1 rgbRed; //红色分量
BYTE1 rgbReserved; //保留(0),非0则为alpha通道
} RGBQuad;像素
typedef struct _RGBPx
{
BYTE1 R; //红色分量
BYTE1 G; //绿色分量
BYTE1 B; //蓝色分量
} RGBPx;
当图像颜色为24位时,即为全彩色RGB模式,无颜色表,所有颜色皆为重要色,因此biBitCount=24时文件中没有RGBQuad区域;若biBitCount为其他值,则图像为索引模式,颜色表中包含图像所用到的颜色,RGBQuad区域为RGBQuad结构体数组。文件中文件头(BitmapFileHeader),信息头(BitmapInfoHeader),颜色表(RGBQuad)三个区域之后是像素矩阵区域。
像素矩阵区中对于24位全色彩文件是RGBQuad区域为RGBQuad结构体数组,对于索引模式图像会将颜色表按照先后顺序编号,例如4位颜色,16色,将会编号0~15号颜色,如此0000b(1)表示第1种颜色,0001b(2),0010b(3),0011b(4),0100b(5)……故一字节可以表示两个像素,如0xa2=10100010b即为11号和2号色。
关于像素矩阵中还有一个问题需要注意,那就是“4字节边界”。像素矩阵的存储是遵循4字节边界存储的,也就是说每一行像素的数据字节大小必须是4的倍数,可是实际上有些图片存储后并不能保证每行的字节数是4的倍数;如一幅1366*768的24位图像,这种图像一像素24位即3字节,则每行1366*3=4098字节,而4098%4=2,余2并不是4的倍数,此时应当在最后2字节后面补充2字节(0x0)。故,在读取时应当注意每行像素后面是否有空边界。
最后,读取的像素还要进行倒置才能够正确的显示,因为原像素矩阵是上下颠倒,左右颠倒的。
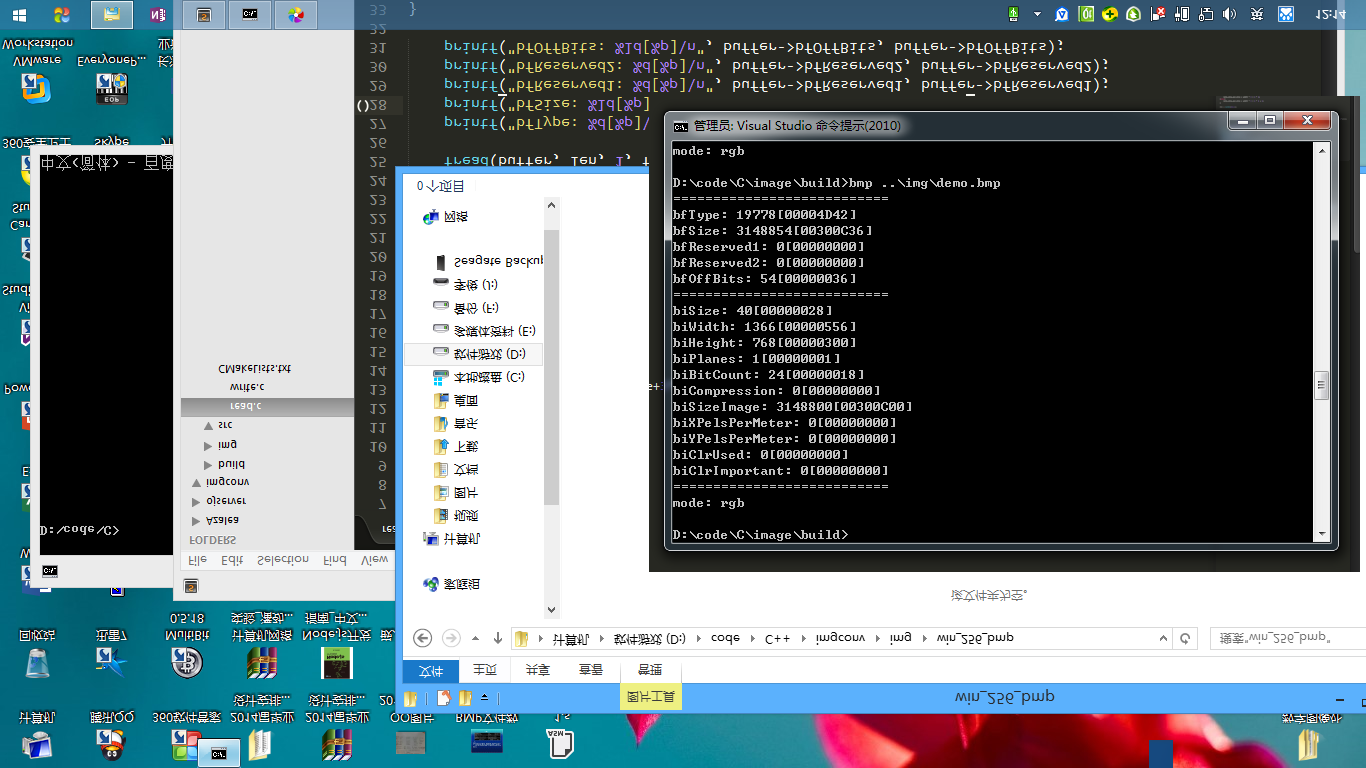
最后附上我自己实现的零依赖的bmp解析项目,直接读取二进制bmp文件解析,并带有基础图像变换函数https://github.com/organc/image 。




 粤ICP备2022112217号
粤ICP备2022112217号